Language as a Prediction Problem
Published March 15, 2026
Philosophy is written in this grand book, the universe, which stands continually open to our gaze. But the book cannot be understood unless one first learns to comprehend the language and read the letters in which it is composed. It is written in the language of mathematics, and its characters are triangles, circles, and other geometric figures without which it is humanly impossible to understand a single word of it; without these, one wanders about in a dark labyrinth.
~ Galileo Galilei, The Assayer (1623)
Most people who encounter a language model assume language means the same to models as it does to us. That the word “cat” brings a mental image, a memory, a feel of fur. It doesn’t. Language models don’t learn what a cat is like we do. What they learn is which words appear near “cat,” and which words appear near those words, and the patterns in which they are arranged across billions of sentences.
That is different from what we call understanding, but it turns out to be surprisingly powerful.
This chapter sits between the section on what AI is and the one on LLM architecture — a bridge from the high-level and the technical details. By the end of it, you’ll have a good enough picture of what these systems actually do that when someone says a model “understands” or “reasons,” you’ll know what that means. It covers what “language” actually means to an LLM, why prediction is a surprisingly direct proxy for genuine representation, how that representation evolved from counting sequences to geometry, and why scale produced capabilities nobody designed.
Language in a language model
“Language” in a language model means any structured system with symbols that possess statistical regularities. Not just human speech. They were called that way because they were first trained on, and designed for, natural language. But the name has outlived the original scope.
They performed well on images, audio, video, protein sequences, and code for the same reason they operated on text: all of these are sequences with a statistical structure, where patterns carry information and predicting well requires learning the rules.
When these systems began processing data beyond text, the core mechanism didn’t fundamentally change — everything gets converted into the same basic unit of language, then passed through a similar machinery. We’ll learn about the basic unit of language in this chapter, and the machinery in the next.
As their capabilities have expanded, “foundation model” has become an increasingly common label. But LLM as a term still dominates.
Prediction as a form of intelligence
If language contains hidden patterns, then a model’s job is to find them. Turns out, one of the most direct tests of whether you’ve found them is whether you can predict what comes next.
This is similar to something observable in people who are consistently right in their domains. The entrepreneur who recognizes a problem that others don’t, the scientist who comes up with a good hypothesis — their accuracy is evidence of an internal model of how the world works. Accuracy of prediction is a signal that something deep has been captured. The deeper that insight is, the more likely it is to transfer into other domains, or, as it’s called in computer science, the more likely it is to generalize.
Take a more relatable example: if you know a person well, you can accurately complete their sentences. You’ve built a representation of how their mind works and that allows you to accurately read their mind.
Language models are built on the intuition that accurate predictions require genuine representation. You can’t fake your way to consistently correct outputs, in a wide variety of settings, without having learned something real about the world in which you’re predicting.
The difference is that in the case of the model, the prediction task is explicit and is optimized directly. Every parameter in the model gets adjusted in the direction of better prediction.
Next-word prediction as a path to general capability
We saw that prediction is a good proxy for intelligence. But prediction is not a single thing. If you decided to train a model to predict, your first question would be: predict what?
You could predict the sentiment of a sentence. You could predict whether two paragraphs are about the same topic. You could predict whether a translation is correct. All of these are prediction tasks. Early models tried these and they were useful but narrow. A model trained to predict sentiment can only do that. It doesn’t learn much else. And every one of these tasks requires labeled data: a human has to go through thousands of examples and attach the right answer before the model can learn anything, because the right answer isn’t found in the data itself.
Next-word prediction, on the other hand, looks like just another option on that list — a particularly constrained one, since you’re only ever predicting a single word ahead. But it wins for the following reasons.
First, it requires no labels. The text itself is labeled data. If the sentence “A cat is a cute, furry, little animal” was found in the training data, “cute” is the label for “A cat is a”, “furry” is the label for “A cat is a cute, ”, and so on. Unlike sentiment or other kinds of prediction tasks, every sentence in the training data comes with labels for free. This is what allowed the models to train on the scale of the internet.
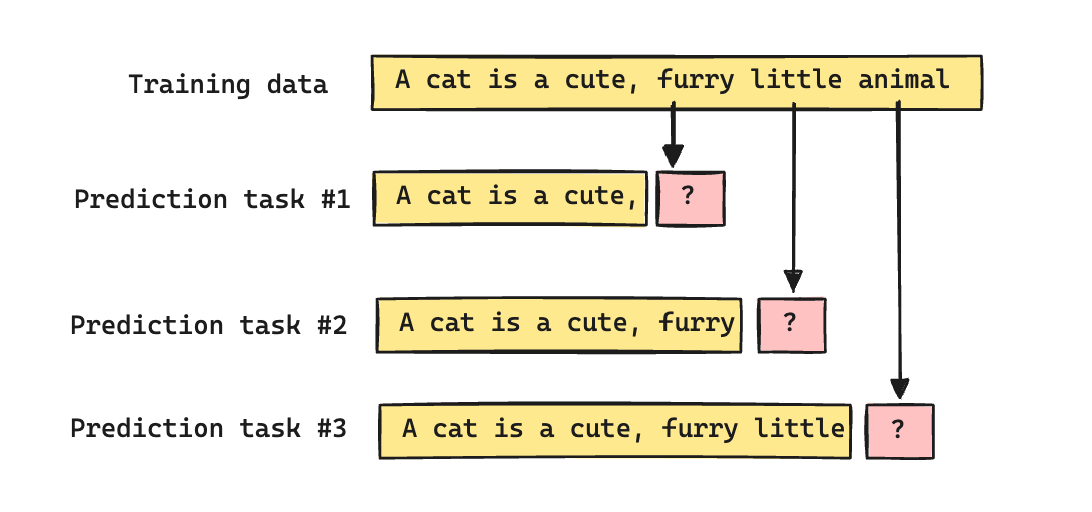
Second, a model trained to predict sentiment is learning one narrow slice of language. A model trained to predict the next word in a diverse corpus is implicitly being tested on everything — fact, grammar, logic, code — because all of these influence what comes next. To predict “The Eiffel Tower is located in ..”, you need factual knowledge. To predict “if A then B, and B then C, therefore ..”, you need logic. The single task of predicting the next word turns out to be a proxy for all tasks, without being designed that way.
Third, as mentioned before, predicting the next word well, across a sufficiently large and diverse dataset, is equivalent to modeling whatever generated the sequences (like the friend’s mind whose sentences you can complete).
Fourth, it seems like a narrow task. You’re predicting one word at a time. But it is less local than it appears. Predicting the next word in the context of everything the model has processed up to that point is a different task than predicting it from the last five words. The latter is a lookup table. The former requires building a compressed representation of all prior context and holding it as you generate the next word.
A good way to think about this is to reflect on how you make decisions. Different experiences at different times carry different weights but the decisions you make today are largely the result of every experience that has shaped you to who you are today, not merely what happened over the last day, week, or month.
But next-word prediction alone still has a structural limitation: it can’t evaluate the intent or quality of the complete output. The objective, by design, has no way to track whether the whole output is good.
You’ve likely seen the equivalent in conversation — someone gives individually sensible words that, taken together, don’t answer the question. It’s what we call word salad.
There are three primary ways the field has added more global signals on top of next-word prediction: by changing what the model is asked to predict, by judging complete responses rather than individual tokens, and by rewarding the quality of reasoning rather than just the final answer.
Changing what gets predicted. If a piece of text is globally coherent, you can reconstruct a missing word from its surroundings. If it isn’t, you can’t — the context gives you nothing to work from.
Consider this sentence:
“Purple running telephone beside justice slowly carpet.”
If I masked one word: Purple running … beside justice slowly carpet, and asked you to predict the word, you’d fail, not because you’re bad at it, but because the surrounding context doesn’t reveal anything to close the gap.
Now try:
“The doctor told her to rest and drink plenty of … to stay hydrated”
Predicting the missing word here is easy because of coherence.
Coherence becomes a prerequisite for filling in blanks well. This intuition is what masked language modeling exploits. It randomly masks words throughout a sequence and asks the model to predict them using both left and right context. The objective becomes more globally contextualized, though it is not inherently generative.
Judging complete responses. Imagine having a hundred people answer the same question, then asking a panel to judge not individual sentences but each response as a whole. You take the winning responses and use them as examples of how to communicate well. The feedback is holistic: the panel isn’t evaluating word choices, they’re evaluating the complete answer.
RLHF (Reinforcement Learning from Human Feedback) is exactly that. It trains a separate reward model on human preferences, then fine-tunes the language model to maximize that reward. The reward is assigned to the complete response, not individual words — an explicit global objective stacked on top of local prediction.
Rewarding the reasoning process. Think about why interviewers ask candidates to think out loud. They’re not primarily interested in whether you give the right answer — they want to see the reasoning. Because reasoning generalizes and specific knowledge often doesn’t. A candidate who arrives at the right answer through flawed logic is vastly different from one who reasons carefully and makes a small error at the end.
Process reward models follow the same logic, but go further: they reward each intermediate reasoning step rather than only the final answer. The model learns that the quality of the path matters, not just the output.
If process reward models are the practice of thinking out loud, the next technique is like the interviewer reminding you to do it.
Chain-of-thought prompting instructs the model to generate explicit reasoning steps before committing to an answer. Rather than training a different objective, it uses the model’s existing next-word prediction capability to build a chain of globally coherent thought first. This technique was initially associated with inference rather than training, but more recent reasoning models train with chain-of-thought generation explicitly; the boundary has been shifting. We’ll cover both in subsequent chapters.
In summary, next-word prediction is more global than we might assume, particularly at scale. But it is inherently limited in ways that require creative additions to align it with broader, more holistic success criteria.
Note that this section uses the word “word” and “next-word” as a simplification, though language models work on a different fundamental unit: tokens. We’ll learn about it later. For the goals of this section, using words instead of tokens still retains the essence.
From n-grams to neural language models — the conceptual leap
You can predict the next word in broadly two ways: by memorizing what comes after a certain sequence of words, or by learning the meaning of those words.
When my kids were little, they were like parrots. They could repeat what I said and finish sentences they had heard before. When I said “When you’re wrong, you should always say…”, they completed it with “sorry.” When I said “When you want something, always say…”, they said “please.” But if I said the same thing in a different way, they’d stall. It’s as if the familiar sequence had created a simple lookup table in their brain. Given the right input, they retrieved the right output. They hadn’t understood what those sentences meant… yet.
This is essentially the n-gram model. It estimates the probability of the next word from the frequency of that word following the prior N words in the training data. If N is five, you’re predicting from the last five words. It works when what you’re predicting appears in the training data. It fails at anything else. The model rests on memorizing sequences of words rather than understanding that those sequences mean.
After a few months, my kids started doing something different. They were forming sentences they had never heard before, which meant they had internalized not just words but a grammar that connected them, and some sense of meaning that made new constructions possible. They had gone from memorizing to building a better representation of the language.
The technical equivalent of that shift was a proposal to stop treating words as discrete units to be counted and matched, and instead represent each word as a point in a continuous high-dimensional vector space — learning those representations jointly with the prediction task. If you capture a word from enough angles simultaneously, similarity in meaning becomes proximity in geometry: words used in similar contexts end up near each other in space. This was Yoshua Bengio’s proposal in 2003.
A decade later, a team at Google showed the geometry wasn’t merely proximity — it encoded relationships. You could take the vector for “king,” subtract “man,” add “woman,” and you landed close to “queen.” The same arithmetic worked for capital cities, verb tenses, comparative adjectives. The geometry had learned something real about the structure of language, without being told what that structure was. This is Word2Vec, and it made the promise of learned representations concrete.
Intuition behind high-dimensional vector spaces
Let’s see why (and how) words can be represented as points in space and what the dimensions in that space are.
Try this: write a description of a cat. It might go something like this — a small, furry animal with a long tail and large whiskers. It sleeps a lot. It doesn’t particularly like being held. It meows and purrs. It can jump from high surfaces and land safely. It chases small animals: mice, insects.
Now write a description of a dog: a human-friendly animal that comes in many sizes. It likes being cuddled. It’s emotionally attached to its people. It barks, runs fast, wags its tail. It chases things too.
Unknowingly and naturally, you have reached for some common themes in both descriptions: size, physical form, sound, behavior, emotional character, predatory behavior. These are implicit dimensions — the aspects you use to characterize an animal without being told which aspects to use.
If you extract those as axes and your descriptions as values, “cat” and “dog” become points in a space you could describe with a vector (a list of values):
[size: small, sound: meow, nap time: long, emotional attachment: low, ability to climb: high].
Now compare the vectors for “cat” and “lion.” They’d be close on many axes — both feline, both carnivorous, both capable of climbing — and distant on others: size, domesticity. Closeness in vector space captures something real about closeness in meaning.
In this simple example, the dimensions used to represent the animals in space are explicit from our descriptions. Although the models conceptually do something similar, there are important differences.
First, they find those dimensions from analyzing the context in which those words appear in the training data. Through the sheer volume of the data they’re trained on, they’ll inevitably find important characteristics of a cat and a dog based on what the data says about them.
Second, LLMs operate in spaces of thousands of dimensions — 1,024 to 4,096 is a reasonable range for many models, and frontier systems push well beyond that — rather than the handful in our example.
Third, the dimensions in the example above are human-readable: you could look at an axis and say “this is about size” or “this is about sound.” The dimensions learned by a real model are not. They’re abstract, numeric values, learned entirely from patterns in text. No single dimension corresponds to a concept you could name. The “cat” vector has 1,024 coordinates, yet none of them means “size.” The geometry is real — similar words do cluster — but the axes are uninterpretable to humans.
A model compensates for its lack of semantic understanding by greatly expanding the number of dimensions across which it can identify patterns.
Tokens and embeddings: how LLMs represent and process text
“You shall know a word by the company it keeps.”
~ J. R. Firth
So far we’ve treated ‘word’ as the fundamental unit of language. And it is, for humans. But computers work better with numbers than with words, and these models process more than just human language, so ‘word’ isn’t the right unit. A ‘token’ is.
So before a model can do anything useful, it needs to have a way to tokenize the language.
The input — text, an image, audio — gets broken into discrete chunks: tokens. For text, these are subword fragments. For an image, small rectangular patches. For audio, short slices of the waveform. Then each chunk gets assigned a unique integer from a fixed vocabulary. That integer is what the model actually receives. A sentence like “the cat sat” might become [464, 2857, 3290]. That’s the input. The number 464 doesn’t mean anything about cats. Think of it as a unique tag the tokenizer gives to what we see as “cat.”
So chunking is the strategy. The next question is: what’s the right chunk size?
For simplicity, let’s consider text.
Let’s look at how we work with languages. We don’t think in individual letters. We largely think in words. But at a deeper level, we instinctively also analyze subwords. When we see the word “unhappy”, we think of it as “un” and “happy”, or when we see “misrepresent”, we think of “mis” and “represent”, to make sense of the word. And over time we learn what those prefixes do to the word that they get tacked on to, which lets us predict the meaning of newer words like misconstrue.
Similarly for a model, characters are too small a chunk. Sequences become very long, and the model has to do enormous work to learn that “c,” “a,” and “t” together constitute something. Words are too large. The vocabulary explodes — every plural, every tense, every piece of code becomes a separate entry, and words absent from training are hard to handle.
Subword tokenization resolves this by noticing that language has statistical structure at multiple levels at once. “Run,” “running,” and “runner” share something. “Unhappy,” “unfair,” and “unwanted” share something. A tokenizer can discover those fragments automatically by finding sequences that appear together often enough to be worth treating as a unit. “Un-” shows up before enough words, consistently enough, that it becomes its own token. The tokenizer doesn’t know that prefix signals negation. It just sees a recurring pattern. That’s enough for it to be useful.
The units of language smaller than words that carry consistent meaning — prefixes, suffixes, root words — are called morphemes. Subword tokenization rediscovers morpheme-like patterns from statistics alone, without any knowledge of the language built in.
But tokenization alone is still a lookup table. Each token is a discrete symbol. Two tokens can be related in every sense — “run” and “sprint,” or “king” and “queen” — and the tokenizer treats them as completely unrelated entries. It doesn’t help you learn that “run” and “sprint” — two words that don’t appear to have anything in common — are indeed closer in meaning than “run” and “king.”
To go from tokens to something closer to meaning, we need embeddings.
The J. R. Firth quote at the beginning of this section captures the intuition behind embeddings clearly. A word’s meaning isn’t merely a definition — it’s a pattern of association. “Cat” means what it means because of how it appears alongside “purr,” “fur,” “independent,” and not alongside “bark” or “loyal.” Meaning as neighborhood.
Here’s an analogy: Your friend might describe their manager in excruciating detail at different points in time, which builds a mental model of the manager, without you ever meeting them. It’s built from all the things you’ve heard about them. Geometrically, you’d place that person in a space whose axes are built from the various ways the manager is described in different contexts:my manager doesn’t care about my growth, my manager rides a bike to work, my manager is technically strong but lacks empathy, he has been in the company for a decade, and so on.
This is what embeddings do. The embedding step converts each token into a vector in high-dimensional space — the kind described in the previous section. And critically, those vectors are learned, not assigned. As the model trains on sequences of tokens and tries to predict each next one, it adjusts every embedding to reduce prediction error. Words that appear in similar contexts end up with similar vectors, because similar contexts produce similar prediction pressures. No one specified that “king” and “queen” should be close in vector space. The model discovered it, because they appear in similar contexts. Because they keep each other company.
The result is that proximity in embedding space encodes something real about proximity in meaning — and that representation can generalize. A model with well-learned embeddings can handle words in contexts it hasn’t seen before, because similar words have similar representations.
Implications of scale: emergent capabilities and the scaling hypothesis
The shift from n-grams to embeddings represents one kind of leap: from memorization to representation. The next question was whether making everything larger — more parameters, more training data, more compute — would yield better performance. The answer turned out to be yes, and not only in ways people had anticipated.
In 2020, OpenAI published what became known as the scaling laws paper. Its finding was that performance on language modeling tasks improves predictably with scale. Model size, training data volume, and compute all contribute, and the relationship follows a power law (increasing the scale reduces the prediction error in a predictable way). This meant you could forecast how a model would perform before building it.
Note: A power law describes a relationship of the form output = input^k, where the output changes not by a fixed amount as input grows, but by a fixed ratio. The exponent k determines the shape: when k is greater than 1, output accelerates; when k is less than 1, you get diminishing returns. In scaling laws, k is less than 1: doubling compute reduces loss, but by less than the previous doubling did. A useful property of a power law is that applying log to both sides and log(output) = k × log(input) makes it a straight line, a linear relationship.
Not only did performance improve as expected at scale, the models started doing things that it was not expected to do, and certainly not designed to do.
Below certain parameter thresholds, you have a system that is very good at predicting the next token — useful, but bounded. At certain thresholds, new capabilities appear that weren’t part of the training objective and weren’t anticipated. GPT-2, at 1.5 billion parameters, produced fluent text but couldn’t generalize from a few examples in the prompt to new examples of the same pattern without additional training. GPT-3, at 175 billion parameters — roughly 100 times larger — could. That capability, called few-shot in-context learning, wasn’t designed into GPT-3. It appeared. This is what got called an emergent capability: an ability that is absent below certain thresholds and present above them, without being explicitly trained for.
Consider what happens when you heat water.
Until the temperature reaches 100°C, the water just gets hotter — a gradual, continuous change. Then at 100°C, something new occurs: the water doesn’t just get hotter, it changes state entirely to vapor. The quantitative change crosses a threshold and produces something qualitatively different.
Unlike the phase transition in water which is sharp and universal, emergent capabilities in language models are fuzzier. They vary across models and benchmarks, appear at different scales for different tasks, and the threshold isn’t predictable in advance. Also worth calling out that whether these capabilities are truly emergent is contested. But regardless, model capabilities increased dramatically and in unexpected ways through scaling, while the architecture and algorithms remained largely unchanged. And that reshaped research priorities, investment patterns, and the physical infrastructure of the entire industry.
What scale forces is a more complete representation of the knowledge contained in the training data. More parameters means more capacity to hold patterns, relationships, and abstractions.
What this picture arms you to push back on
LLMs are frequently described as “understanding” language, “reasoning,” or “knowing” things. These words import assumptions worth holding carefully.
What LLMs demonstrably do: find statistical patterns in sequences, represent tokens as vectors in high-dimensional space, and generate outputs by predicting each next token in light of everything that preceded it in the context window. They generalize from training data in ways that are often genuinely impressive and immensely useful.
What they don’t do, at least not in the way humans do: ground symbols in embodied experience, or maintain beliefs over time. The word “cat” in a language model is a point in a vector space whose coordinates were shaped by patterns of co-occurrence in text. It is not connected to the sensation of touching fur or the memory of a particular animal.
This framing that prediction is a form of intelligence in the way LLMs do it is contested. The position of critics is that statistical competence — predicting which tokens follow which — doesn’t constitute intelligence.
Intelligence here is used in a narrow, functional sense — the capacity to make accurate predictions across diverse domains — not in the richer philosophical sense that requires grounding, agency, consciousness, or embodied experience.
Where this leads
This chapter traced how a language model represents and learns from sequences: what “language” means in this context, why next-token prediction is a surprisingly powerful training signal, how representation evolved from counting sequences to geometry, and why scale pushed capability further than anyone designed.
What we’ll see next is the mechanism that actually processes sequences and captures long-range relationships between tokens. The embedding step converts tokens into vectors. But the model still needs to figure out how any given token should be interpreted in light of all the others — which words in a long passage are relevant to which other words, and how that relevance should shape the prediction.
That’s the attention mechanism. That, along with the transformer architecture, is largely why we got ChatGPT, Gemini, and Claude.
Further reading
The Bitter Lesson Sutton, R. (2019). The Bitter Lesson. incompleteideas.net. A one-page essay arguing that general methods which scale with computation consistently beat hand-crafted domain knowledge — the philosophical grounding for why a general prediction objective on diverse data wins over narrower, specialized ones.
The foundational scaling paper Kaplan, J. et al. (2020). Scaling Laws for Neural Language Models. OpenAI. The paper that established the power-law relationship between compute, data, parameters, and loss. Read this to understand why the scaling era happened when it did — it turned investment in scale from a bet into an engineering calculation.
The correction to the foundational paper Hoffmann, J. et al. (2022). Training Compute-Optimal Large Language Models. DeepMind. (The Chinchilla paper.) Found that Kaplan et al. underweighted data relative to parameters. Equally important for understanding how to scale, not just that you should.
The paper that named emergence Wei, J. et al. (2022). Emergent Abilities of Large Language Models. Google Brain / Stanford. Where the term “emergent capability” was formally introduced and catalogued across tasks. Read alongside Schaeffer et al. to hold both sides of the debate.
The paper that challenges emergence Schaeffer, R. et al. (2023). Are Emergent Abilities of Large Language Models a Mirage? Stanford. Argues that apparent discontinuities are partly measurement artifacts. The best single source for understanding the contested nature of the emergence claim.
The GPT-3 paper (where emergence was first observed, before it was named) Brown, T. et al. (2020). Language Models are Few-Shot Learners. OpenAI. The paper where few-shot in-context learning appeared for the first time at scale. Primary source for the GPT-2 vs. GPT-3 comparison.
The paper that started learned word representations Bengio, Y. et al. (2003). A Neural Probabilistic Language Model. Journal of Machine Learning Research. The first proposal to learn word representations jointly with a language model. Short and foundational — the conceptual origin of modern embeddings.
Word2Vec and the king–queen arithmetic Mikolov, T. et al. (2013). Efficient Estimation of Word Representations in Vector Space. Google. The paper behind the famous vector arithmetic (king − man + woman ≈ queen). Short and readable — the best introduction to what geometry in embedding space can do.
Visual intuition for embeddings Alammar, J. The Illustrated Word2Vec. jalammar.github.io. Not a paper, but probably the best visual explainer of word embeddings in existence. The spatial thinking in this chapter maps directly to what Alammar illustrates.
Follow the book as it's written.
Get notified when a new chapter is ready.
No noise, just the work. Unsubscribe anytime.